As a continuation of my post the other day about Protocols as a better design approach than Platforms, I want to offer more details about how ATProto and Bluesky work.
So Bluesky is this decentralized social network that distributes control across multiple servers, built on the open-source ATProto framework. Bluesky uses a federated architecture render the familiar client-server model of traditional social media. But Bluesky is anything but "traditional".
Bluesky defines distinct data schemas and API endpoints for ATProto apps, storing each user’s published data in a dedicated repository backed by SQLite. Every user action (such as likes or comments etc) lives in that repository(database). Also each individual user gets their own personal repository (database) that stores primary data (who a user follows, posts the user has created, etc), separate from their actions. So these repositories reside on a data server, exposing the data to the index server and clients via http access (and users can store their personal respository on their own personal data server-we will circle back to that in a bit).
Bluesky then uses a crawler service which collects data from each repository, and forwards it data in streams over WebSockets to an index server. The index server then processes the data stream, hunting for total likes and comments on posts (and the total counts of likes / comments).
Bluesky stores Media files (e.g., images) on the data server where they get referenced in the repositories. On user requests, the index server fetches these media files from the data server. These fetches get cache on a CDN.
tl;dr for fhe above:
Each individual Bluesky user gets their own personal database that stores their follows, posts, and so forth (PDS). This is used to locate their likes / comments which are stored elsewhere. By defaut Bluesky creates/registers and hosts this personal database on Bluesky data servers, which fetches your data and merges it with everyone else’s to generate your feed-on-the-fly. You're even store your personal database just about anywhere else outside of Bluesky's infrastructure: giving you total control of your "identity" and social media activity.
Here's a handy visual flow of what I describe above, from Bluesky's October 2024 Whitepaper on how all this works:
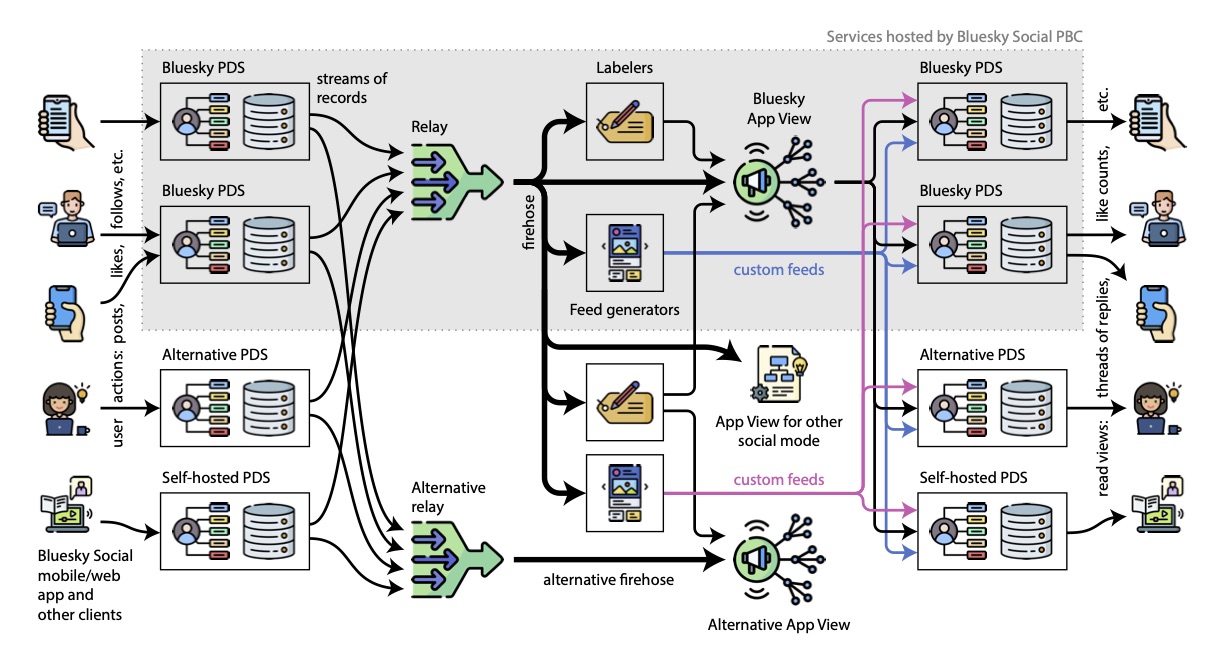
The main services involved in providing Bluesky, and data flows between them.
So each user repository(database) stores primary data, while the index server stores data derived from repositories. A user updates only their repository when they follow someone or write a post. Other The index server must keep up with all this, and so consequently it is the most resource-intensive part of the overall Bluesky service. Thus, the index server is big on caching results. Results get cached in Redis, via in-memory database, to optimize performance.
Based on this flow, here is what is happening for posts displayed on your timeline:
- A user’s request is routed via their data server to the index server.
- The data server finds the people a user follows by looking at their repository.
- The index server creates a list of post IDs in reverse chronological order.
- The index server expands the list of post IDs to full posts with content.
- The index server then responds to the client.
The user’s timeline is rendered during this request, and shows posts to the user in reverse chronological order. Since a user's personal repository doesn’t contain information about likes / comments on a post, the index server is queried for this-and it returns this data during the timeline render, with aggregated data.
What I find revolutionary about ATProto + Bluesky is: users don't have to store their own personal repository on Bluesky's data servers at all. You own it! So you can have your own PDS and store your personal repository virtually anywhere on your own. This takes away the lock-in that places like X-Twitter, where if you use a different social media servers - you have to "start all over" finding people you follow, etc. More on that here.
Wrapping Up
This represents the basics of how Bluesky functions when you refresh your timeline, yet it is practically revolutionary compared to Twitter(X) and other legacy social media: because all this happens in a decentralized manner, where the user ratains standaridized-controls over their own data and their timeline experience. For instance, because of Bluesky design-choices, ussers get a ton of feed and content customization capabilities that the other services just cannot scale to provide. Nor do older social media services want to offer a framework of deep customization, when it comes to algorithsm and influencing your attention. There always competing interests of Ad-buyers and feckless owners of legacy social media services, and they would prefer you not be able to deeply curate your timeline feed!
I may go deeper on more of this in the coming weeks, as this constitutes just the basic fundamentals of how ATProto and Bluesky function-they are a huge shift in design from how legacy social media evolved. Bluesky supports feeds with custom logic (and there are nearly 60K custom feeds available), as well as a number of moderation features available to individual users get to control and manage if they want. This all means you can have multiple focused, targeted timelines that are not directed by any single algorithm or owned/influenced by any social media service owner. This results in a feed that has a better signal-to-noise setup (and is quite a bit less troll-happy over time).
Bluesky's approach permits a timeline that balances being "less noisy" with FOMO (e.g. you won't miss stuff, but you need not see stuff you don't wanna see, either...) And the above "how-it-works" flow (as clumsy as I might be, in explaining it) is part of why Bluesky is even able to a potentially saner timeline.
Here are some helpful articles, and video, used in creating this post.
https://arxiv.org/pdf/2402.03239
https://docs.bsky.app/docs/advanced-guides/federation-architecture
https://www.cl.cam.ac.uk/research/security/seminars/archive/video/2024-11-22-t224767.html